Как вы знаете, есть такой замечательный продукт StarWind Enterprise HA, который позволяет создать отказоустойчивое хранилище для серверов VMware vSphere или Microsoft Hyper-V с помощью технологии iSCSI на базе одного или двух обычных Windows-серверов (то есть не надо покупать дорогостоящие FC-хранилища и продукты для репликации данных). Мы уже писали о нем тут, здесь, там, в этой статье и много где еще. Сегодня мы посмотрим на то, в каких режимах могут работать хранилища StarWind Enterprise.
Итак, при добавлении iSCSI Target в StarWind Enterprise нам предлагают создать новый виртуальный диск. У нас есть три варианта создания диска:
Эти варианты работы iSCSI устройства StarWind отличаются следующим:
В режиме Physical - мы монтируем физический диск сервера для создания iSCSI Target (то есть, с какой-либо файловой системой или без нее). На этом диске хост-серверы виртуализации VMware ESX уже сами будут создавать файловую систему (VMFS).
В режиме Basic Virtual мы создаем виртуальный диск без функциональности снапшотов (то есть это просто файл на диске в операционной системе Windows Server с установленным StarWind Enterprise, в который будет происходить запись данных виртуальных машин, которые, в свою очередь, видят содержимое этого файла как хранилище iSCSI). Внутри этого файла уже самим сервером VMware ESX создается том VMFS. Данный диск может быть тонким (растущим по мере наполнения данными), но создать тонкий диск из GUI StarWind нельзя (будет в следующих версиях).
В режиме Advanced Virtual - мы создаем диск с поддержкой мгновенных снимков и кластеризации. Такой диск работает как предыдущий за исключением возможностей защиты данных. К ним относятся зеркалирование образов дисков, снапшоты (мгновенные снимки) и диск с поддержкой двухузловой конфигурации StarWind (High Availability). Этот тип поддерживает возможность создания тонких (растущих по мере наполнения данными) дисков.
Далее есть три типа виртуальных дисков Advanced Virtual:
Они представляют собой следующие подтипы:
Mirror (RAID-1) Device - это зеркалированный виртуальный диск, который может находиться на разных физических устройствах, подключенных к серверу хранения, что обеспечит защиту данных в случае отказа одного из этих устройств (например, разные диски или разделы разных массивов). Но узел StarWind, через который сервер VMware ESX будет получать доступ к хранилищу, будет один. Такой тип дисков подходит для защиты данных виртуальных машин от физических сбоев хранилищ, но не подходит для защиты данных от утери (например, удаление пользователем).
Snapshot and CDP Device - это возможность создать хранилище виртуальных машин, которое поддерживает функциональность мгновенных снимков (snapshots). Эти снимки могут создаваться автоматически или вручную, что обеспечит возможность отката к определенному состоянию хранилища. Данный тип дисков также может работать в нескольких режимах обеспечения защиты данных. Также эти диски могут быть тонкими (растущими по мере наполнения данными). Кроме того, такой тип дисков может пригодиться, когда часто требуется откатываться к исходному состоянию хранилища, например, при разработке и тестировании.
High Availability Device - данный диск совместим с двухузловой конфигурацией StarWind Enterprise HA, которая обеспечивает защиту данных виртуальных машин за счет резервирования и узлов, и их хранилищ. Эти узлы синхронизируют данные между собой и могут работать в Active-Active или Active-Passive конфигурации (подробнее здесь). Для такого диска указываются параметры сервера-партнера StarWind.
На этом пока все - в следующей заметке мы расскажем о типе дисков Snapshot and CDP Device - в каких режимах они могут работать, и как они могут применяться на практике.
Скачать пробную версию ПО StarWind Enteprise HA можно по этой ссылке. Купить StarWind можно в компании VMC.
Не секрет, что в мире виртуализации есть не только VMware. Многие пользователи, особенно из сегмента малого и среднего бизнеса, отдают предпочтение гипервизору Microsoft Hyper-V, который в составе Windows Server 2008 R2 приобрел множество полезных возможностей.
Технология построения отказоустойчивых хранилищ на базе ПО StarWind Enterprise отлично вписывается в сегмент СМБ, где при небольших инвестициях нужно получить максимум эффективности и функционала. Microsoft Hyper-V дешевле VMware vSphere (именно сам продукт, а не стоимость владения), а StarWind - не требует покупки дорогостоящих хранилищ и недешевого SAN-оборудования. Поэтому Microsoft Hyper-V и StarWind - отличные друзья.
Как многие помнят, у Hyper-V есть псевдокластерная файловая система CSV (Cluster Shared Volumes), которая представляет собой надстройку над NTFS и позволяет использовать общие тома для хранения виртуальных машин с поддержкой "горячей" миграции между хостами Hyper-V (Live Migration) и отказоустойчивости (High Availability). Система эта псевдокластерная потому, что для томов CSV из узлов Hyper-V в кластере выбирается узел-арбитр, который управляет SCSI-резервациями виртуальных машин (сам ввод-вывод идет напрямую).
При этом, у узлов Hyper-V есть такая интересная возможность, как Dynamic I/O Redirection. Эта техника позволяет в случае отказа пути одного из узлов Hyper-V к IP-сети хранения перенаправить его ввод-вывод через узел-арбитр. То есть в случае отказа всех путей хост-сервера к SAN виртуальные машины продолжают свою работу на этом узле до того, пока они не переедут на другой узел за счет технологии Live Migration (картинка уж извините от NetApp):
Если же отказ произойдет внутри iSCSI SAN, то там уже свою работу делает StarWind Enterprise HA, который переключается на резервную ноду без простоя в случае отказа основного узла хранилища.
Понятное дело, что ситуация, описанная выше с Hyper-V для Dynamic I/O Redirection, полезна лишь в очень ограниченном количестве случаев, когда, например, подключения узла к SAN не дублированы (да, и такое бывает).
Мы рекомендуем использовать StarWind Enterprise для конфигураций Hyper-V, когда требуется создание надежной и защищенной инфраструктуры хранения для виртуальных машин. Что еще можно почитать на эту тему от StarWind:
Как вы знаете, есть замечательное ПО StarWind Enterprise HA, которое позволяет создать отказоустойчивое хранилище для виртуальных машин VMware vSphere или Microsoft Hyper-V, на базе технологии iSCSI. Мы уже писали о StarWind здесь, здесь, здесь и здесь, а сегодня мы расскажем о том, какие требования к узлам предъявляет ПО StarWind Enterprise.
CPU
Рекомендуется процессор Intel Xeon E5620 или выше либо эквивалентный ему AMD Opteron. Надо отметить, что рекомендуется использовать многоядерные CPU. При этом, если сравнивать CPU, у которого частота каждого из ядер меньше, с CPU с большей частотой ядер, но меньшим их количеством - то предпочтителен первый вариант. То есть, лучше иметь 6-ядерный Intel Xeon 5660 с частотой 2.8 ГГц на ядро, чем 4-ядерный Intel Xeon 5667 с частотой 3.02 ГГц на ядро.
RAM
Минимум нужно 4 ГБ (для самой Windows и движка StarWind). Если вы используете один из методов кэширования в StarWind - то потребуется дополнительная память на кэши, исходя из их размеров.
Network
Естественно нужно использовать как минимум гигабитную сеть хранения iSCSI (при этом помните, что каждый компонент сети должен поддерживать 1 Гбит). Лучше использовать NIC Teaming для расширения канала или сети 10G, а также большие кадры Jumbo Frames (9K). Помните, что канал синхронизации между узлами обязательно нуждается в дублировании.
HDD
Можно использовать устройства SATA, SAS или SSD. Естественно, используйте аппаратные RAID-массивы, а не программные в производственной среде. Узнавать о том, какой RAID лучше начните отсюда.
Операционная система
Рекомендованная - Windows Server 2008 R2. Можно использовать и Windows Server 2003 (все, что выше - поддерживается). Также можно использовать и издания Server Core и даже бесплатный Hyper-V Server, однако, по понятным причинам, GUI для StarWind нужно будет устанавливать на отдельный компьютер (этот компонент называется StarWind Management Console). При этом для управления можно использовать и рабочую станцию с ОС, начиная с Windows XP. Помните, что для управления надо открыть порт 3261 в сетевом экране.
Сам процесс установки и настройки ПО StarWind Enterprise на каждом из узлов занимает 10-30 минут, поэтому просто возьмите и попробуйте продукт бесплатно.
Многим пользователям платформы виртуализации VMware vSphere известна компания StarWind, которая производит продукт StarWind Enterprise для создания отказоустойчивых хранищ под серверы VMware ESX (описание работы - здесь, изданий - здесь). Основная фишка данного продукта - использование двухузлового кластера, работающего в режиме Active-Passive или Active-Active, который в случае падения одного из узлов продолжает свою работу, а виртуальные машины не теряют данных. Эта вещь актуальна для организаций, которую используют существующую инфраструктуру Ethernet для создания сети хранения на базе технологии iSCSI. То есть для тех, кто не любит тратить деньги направо и налево, покупая Fibre Channel системы хранения.
По заявкам наших читателей мы публикуем объяснение работы кластера StarWind Enterprise в случае обрыва канала синхронизации между узлами (так называемый сценарий Split Brain). В актуальной версии StarWind Enterprise 5.4 при обрыве канала синхронизации между узлами обе ноды оставались работающими, думая что каждая из них - выживший член кластера.
В этом случае, например, при алгоритме балансировки Round Robin (или при переключении пути после разрыва канала синхронизации) могла выйти ситуация, когда данные писались то на одну ноду, то на другую (а данные между ними не синхронизировались). Соответственно, при попытке что-нибудь прочитать - мы получали Blue Screen в гостевой ОС. Поэтому настоятельно рекомендовалось использовать дублирование канала синхронизации (NIC Teaming).
В версии StarWind Enteprise 5.5 которая у меня уже есть на руках (и вы можете ее у меня попросить), а у вас будет совсем скоро, ситуация кардинально лучше. Теперь механизм работы кластера StarWind HA следующий:
Когда ноды работают в режиме Active-Active, между ними все равно есть распределение ролей - Primary и Secondary.
Если обрывается канал синхронизации между узлами (нет пинга), то:
По каналу Heartbeat (сеть iSCSI трафика) первичный узел посылает запрос вторичному узлу на то, жив ли он (обычный ping). Если он жив, то первичный узел посылает вторичному узлу команду на отключение всех клиентов (ESX) от этого узла. Соответственно все команды процессятся через первичный узел и ситуации Split Brain не возникает. При налаживании канала синхронизации - оба узла синхронизируются (второй получает данные от первого) и работа в режиме Active-Active продолжается.
Если Heartbeat по сети iSCSI-трафика не прошел. Это значит умер вторичный узел, а не канал синхронизации. Соответственно, ESX продолжает запись на первичную ноду до того, как вторичный узел не придет в себя. После этого опять произойдет синхронизация и кластер StarWind HA продолжит свою работу.
Вторичная нода тоже пингует первичную при разрыве канала синхронизации на случай если упал сам первичный узел, а не канал синхронизации. Если ответа нет - она продолжает работу по записи данных на диск. После восстановления канала синхронизации с этой нодой синхронизируется первичный узел и конфигурация Active-Active восстанавливается.
Скачать продукт StarWind Enteprise можно по этой ссылке. Купить StarWind можно по этой ссылке.
Таги: StarWind, Enterprise, HA, Split Brain, Storage, iSCSI
Часто бывает необходимо заглянуть в логи сервера VMware ESX или ESXi и посмотреть, что там происходит. При обнаружении и решении проблем работы серверов виртуализации с хранилищами логи - это главный источник ваших знаний о том, что с ними случилось.
Если сервер ESX / ESXi работает с хранилищем iSCS или Fibre Channel в режиме multipathing с одним активным путем к хранилищу, то описанная ниже последовательность шагов, которые выполняет ESX, может вам помочь при наступлении события переключения на резервный путь (failover)....
Таги: VMware, ESX, Storage, Multipathing, HA, ESXi, vSphere, iSCSI, FC
Компания StarWind, являющаяся спонсором VM Guru, предлагает своим пользователям один из лучших в индустрии продукт для создания отказоустойчивых хранилищ для виртуальных машин VMware vSphere и Microsoft Hyper-V на базе технологии iSCSI. Преимущество StarWind Enterprse в том, что без существенных вложений в инфраструктуру Ethernet и сам продукт (он недорог) вы можете получить надежную, защищенную от отказов инфраструктуру хранения для виртуализации.
Почитать о принципе работы продукта StarWind Enterprise можно вот в этой статье.
Данное решение можно использовать в сегменте среднего и малого бизнеса, где дорого и сложно (административно) получить бюджеты на отказоустойчивые программно-аппаратные решения Enterprise-уровня. Кроме того, важная тема - создание виртуальной инфраструктуры филиалов, где стоит 3-5 серверов VMware ESX и 20-30 виртуальных машин.
Сейчас продукт StarWind Enterprise предлагается в 3-х изданиях:
StarWind Enterprise CDP (лимит 4 ТБ): Это лицензия на 1 сервер, назначенный в качестве первичного контроллера хранилищ (например, томов VMFS), и включает в себя неограниченное количество одновременных клиентских iSCSI-подключений, поддержку технологии CDP/Snapshot. Это базовая лицензия - здесь нет синхронной репликации данных на резервный узел и самого резервного узла тоже нет.
StarWind Enterprise Mirroring & Replication: Эта лицензия требуется для сервера, назначенного в качестве первичного контроллера хранилища, и включает неограниченное количество клиентских соединений и нелимитированную емкость хранения. Это издание StarWind позволяет реплицировать данные только в одну сторону (на вторичный узел) с первичного узла. То есть, с этой лицензией нельзя использовать два активных сервера хранения, а только активно-пассивную конфигурацию.
StarWind Enterprise HA (лицензия на 2,4,8,16 и неограниченное число ТБ хранения): Лицензия StarWind Enterprise HA включает неограниченное количество клиентских iSCSI-соединений с лимитом емкости или без него для окружений, в которых необходима высокая доступность класса Active-Active (зеркалирование и удаленная репликация) с различным объемом хранения и числом серверов-контроллеров хранилищ. В рамках лицензии можно использовать одну или две пары серверов в конфигурации Active-Active.
Внимание: для всех изданий StarWind Enterprise в стоимость продукта уже включен 1 год технической поддержки и подписки на обновления. То есть, отдельно ее нужно приобретать только для последующих лет эксплуатации решения.
Приятный момент при покупке StarWind - вы покупаете какое-нибудь издание (например, базовое на один сервер), а потом решаете, что вам нужна высокая доступность. Вы делаете апгрейд - и платите только разницу в цене между изданиями, без диковинных наценок, которые появляются, например, у VMware.
Вы уже выучили, где продаются все продукты, о которых мы пишем? Правильно - в VMC.
На сайте myvirtualcloud.net появилась отличная статья, в которой описываются подходы к отказоустойчивости и восстановлению после сбоев (Disaster Recovery) в инфраструктуре виртуальных ПК VMware View 4.5.
Рассматриваются конфигурации Active-Active и Active-Passive для сайтов, где развернуто решение VMware View. Статья обязательна к ознакомлению тем, кто еще не задумывался над этим важным вопросом.
Интересную возможность управления кластером высокой доступности VMware HA демонстрирует Duncan Epping. Если в сервисной консоли VMware ESX ввести команду:
/opt/vmware/aam/bin/Cli
а потом набрать команду:
ln
то мы увидим вот такую картинку:
В колонке Type мы видим значение Primary - это тип узла кластера VMware HA (всего может быть 5 Primary узлов, соответственно виртуальная инфраструктура гарантированно выдерживает до 4-х отказов включительно). Далее можно превратить Primary-ноду в Secondary:
Технология VMware Fault Tolerance позволяет защитить виртуальные машины с помощью кластеров непрерывной доступности, позволяющих в случае отказа хоста с основной виртуальной машиной мгновенно переключиться на ее "теневую" работющую копию на другом сервере ESX. Однако эта технология имеет существенные ограничения, приведенные ниже. Таги: VMware, Fault Tolerance, FT, vSphere, ESX, DRS, DPM, HA, Enterprise
Как уже много писали об этом ранее, одной из проблем механизма отказоустойчивости VMware HA является его потенциальное не срабатывание в окружениях, где одновременно отказывает более 4-х хостов в кластере (например, на уровне блейд-корзины), когда не доступны все 5 primary-узлов. В этом случае есть риск, что виртуальные машины не перезапустятся на оставшихся хост-северах.
В VMware vSphere 4.1 появилась возможность явным образом указать, какие узлы в кластере VMware HA будут являться Primary:
Можно использовать в качестве разделителя пробел или запятую.
Эти настройки необходимо указывать в расширенных свойствах кластера VMware HA (Advanced Settings). Обращаю внимание, что хоть эти настройки и не являются experimental, они являются неподдерживаемыми со стороны VMware и не рекомендуются к использованию в промышленной среде. Кстати, скоро кластер VMware HA будет переживать сколько угодно отказов хостов ESX / ESXi.
Как многие знают, недавно компания VMware выпустила обновление продукта VMware vSphere 4.0 Update 2. Среди прочих нововведений есть также улучшения механизма VMware HA для отказоустойчивости серверов VMware ESX. Одно из улучшений - решение проблемы Split Brain в кластере HA, которое заключалось в следующем:
Если у вас есть несколько хостов ESX, подключенных к IP-системе хранения iSCSI / NFS, а для виртуальных машин выставлено действие Leave Powered On для Isolation Responce (по умолчанию), то при отключении хоста от всех сетей (IP Storage и VM Network) процессы VMX, реализующие исполнение виртуальных машин оставались в памяти.
При этом, по истечении срока действия лочек VMware HA, остальные хост-серверы ESX запускали эти виртуальные машины. Когда соединение выпавшего хоста с сетью и хранилищем восстанавливалось - процессы продолжали жить, что приводило к так-называемому "пинг-понгу" виртуальных машин между хостами ESX и всяким глюкам.
Теперь же, начиная с VMware vSphere 4.0 Update 2 эта ситуация решается - хост ESX выключает виртуальную машину и генерирует соответствующее событие в vCenter.
Большинству пользователей виртуальной инфраструктуры VMware vSphere известны такие параметры как Limit, Reservation и Shares для пулов ресурсов (Resource Pool) в пределах кластеров VMware DRS и отельных хостов ESX. Именно этими тремя параметрами определяется потребление виртуальными машинами оперативной памяти и процессорных ресурсов хоста VMware ESX. Таги: VMware, vSphere, Resources, ESX, HA, DRS
Виртуализация, при всех своих несомненных плюсах, имеет один очевидный недостаток - единая точка отказа в виде системы хранения, где размещены все виртуальные машины. Ситуацию во многом спасает наличие средств по резервному копированию или репликации данных (например, Veeam Backup), однако, эти средства не могут обеспечить полностью непрерывную работу виртуальной инфраструктуры. StarWind Enteprise HA позволяет решить эту проблему.
Механизм VMware High Availability (HA) в VMware vSphere позволяет перезапустить виртуальные машины отказавшего хост-сервера VMware ESX на другом сервере кластера с общего хранилища. Однако, что будет, если один из узлов кластера не сможет запустить виртуальную машину (например, она продолжает работать на изолированном хосте)?
Ответ прост, VMware HA пробует запустить виртуальную машину 5 раз в следующем порядке:
В Advanced Settings для VMware HA может быть добавлен следующий параметр, определяющий число попыток рестарта виртуальных машин (недокументированная возможность):
das.maxvmrestartcount
Если поставить -1, VMware HA будет постоянно пытаться запустить виртуальные машины. Для применения настройки нужно выключить HA в кластере и включить его снова.
Функциям высокой доступности VMware High Availability (HA) уже без малого 4 года. Возможности VMware HA позволяют повысить отказоустойчивость виртуальной инфраструктуры и сделать более непрерывным бизнес компании. Суть возможностей VMware HA заключается в перезапуске виртуальной машины отказавшего сервера VMware ESX с общего хранилища (собственно, сам VMware HA), а также рестарте зависшей виртуальной машины на сервере при потере сигнала от VMware Tools (VM Monitoring).
Между тем, функции VMware HA имеют следующие ограничения:
Хостов в кластере VMware HA - максимально 32 хоста
Виртуальных машин на хост с числом хостов VMware ESX 8 и менее - масимально 100
Виртуальных машин на хост с числом хостов VMware ESX 8 и менее для vSphere 4.0 Update 1 - масимально 160
Виртуальных машин на хост с числом хостов VMware ESX 9 и более - масимально 40
Как мы видим, для крупных инсталляций VMware vSphere в очень больших компаниях даже этих максимумов может не хватить. Поэтому одна из задач компании VMware - увеличивать эти параметры, что и было уже ранее анонсировано в различных дорожных картах.
Второй интересный момент - функции мониторинга доступности гостевой ОС виртуальной машины - VM Monitoring. Если вы откроете vSphere Client и попробуете создать кластер VMware HA, вы увидите, что по умолчанию функции мониторинга доступности - отключены. Как известно, возможности VM Monitoring довольно долго были в статусе experimental, но сегодня они уже доступны для промышленного использования. Однако VMware пока не спешит их ставить по умолчанию - неудивительно, ведь пользователи не раз сталкивались с ситуацией, когда VM Monitoring на ранних этапах своего развития давал сбой и попусту перезагружал виртуальные машины. Здесь задача VMware состоит в техническом усовершенствовании возможностей VM Monitoring, а также постепенное завоевание доверия пользователей.
Следующий аспект - число отказов, которые может пережить кластер VMware HA. Сейчас в кластере HA может быть только 5 primary хостов ESX, чего явно недостаточно для создания катастрофоустойчивого решения на уровне блейдового шасси (его можно назвать possible failure domain). Кроме того, на данный момент нет прозрачного механизма назначения хостов как primary или secondary (например, закрепить primary ноду), что тоже вызывает иногда проблемы. В этом плане компания VMware уже прилагает усилия, чтобы сделать такие кластеры VMware HA, которые будут переживать неограниченное число отказов хостов VMware ESX.
Последний момент - территориальное ограничение кластеров VMware HA. Пользователи VMware vSphere хотят больше функциональности от кластеров, которые должны вести "более подобно" VMware SRM и в полной мере позволять использовать disaster recovery площадку (второй датацентр) для создания "растянутого" кластера. То есть что-то вроде этого:
И это будет! Более подробно о таких кластерах VMware HA и SRM можно прочитать вот в этой статье.
Hany Michael, автор портала Hypervizor.com, опубликовал интересную диаграмму работы механизма обеспечения отказоустойчивости VMware High Availability. На картинке отмечены такие элементы как HA Advanced Settings, HA VM Monitoring, параметры Heartbeats и пинга шлюза, диагностика кластера и конфигурационная информация. Неплохой плакат для системных администраторов, отвечающих за работу кластера VMware HA:
Андрей Вахитов (vmind.ru) в своем блоге разместил просочившуюся информацию о новой функциональности готовящегося к выпуску релиза платформы виртуализации VMware vSphere 4.1, включая ESX 4.1 и vCenter 4.1.
Приблизительный список основных новых возможностей VMware vSphere 4.1:
Поддержка развертывания тонкого гипервизора VMware ESXi по PXE.
Контроль обмена трафиком с системой хранения Storage I/O Control в стиле QoS.
Network I/O Traffic Management - более гибкое регулирование полосы пропускания сетевого взаимодействия виртуальных машин (в том числе сети VMotion, Fault Tolerance).
VMware HA Healthcheck Status - автоматическая проверка работоспособности VMware HA, при этом в случае отклонения настроек кластера от требуемых выдается Alarm в VMware vCenter.
Fault Tolerance (FT) Enhancements - теперь FT полностью интегрирован с VMware DRS, работает в кластерах EVC, а первичные и вторичные виртуальные машины корректно балансируются DRS. Кроме того, VMware FT может теперь работать без VMware HA.
vCenter Converter Hyper-V Import - можно импортировать виртуальную машину на ESX с сервера Hyper-V
DRS Virtual Machine Host Affinity Rules - возможность запрещать некоторые хосты к размещению на них ВМ. Пригодится для соблюдения лицензионной политики.
Memory Compression - новый уровень абстракции оперативной памяти ВМ. Быстрее чем засвопированная на диск память, но медленнее, чем физическая.
vMotion Enhancements - теперь VMotion работает быстрее (до 8 раз), и увеличено число одновременных миграций ВМ на хосте (с 4 до 8).
8GB Fibre Channel Support
ESXi Active Directory Integration - теперь ESXi можно загнать в AD.
Configuring USB Device Passthrough from an ESX/ESXi Host to a Virtual Machine - поддержка USB-устройств на хосте ESX / ESXi, пробрасываемых к виртуальной машине.
User-configurable Number of Virtual CPUs per Virtual Socket - по-сути, многоядерные (не путать с многопроцессорными) виртуальные машины. Несколько виртуальных ядер в одном виртуальном vCPU.
Как может быть вы знаете, компания Citrix поменяла свою стратегию в продвижении продуктов для виртуализации. Раньше флагманским продуктом был Citrix XenApp, обеспечивающий виртуализацию и доставку приложений конечным пользователям на их ПК. Теперь же, компания Citrix выставила вперед решение Citrix XenDesktop 4, ориентированное на доставку окружений пользователям на базе виртуальных машин целиком, при этом решение XenApp уже входит в издания Citrix XenDesktop и работает уже на уровне доставки приложений в виртуальных ПК.
В документе High Availability for Desktop Virtualization от компании Citrix рассматриваются различные аспекты обеспечения отказоустойчивости и непрерывной работы пользовательских окружений на трех уровнях:
платформа виртуализации (Citrix XenServer)
гостевые ОС (потоковая доставка виртуальных ПК и т.п.)
приложения и пользовательские сессии (Citrix XenApp и NetScaler)
В рефернсной архитектуре Citrix XenDesktop рассматриваются также следующие продукты и технологии: NetScaler, XenDesktop Roaming Users and XenServer Pools and XenMotion, которые могут являться частью решения на базе ПО Citrix XenDesktop.
Таги: Citrix, XenDesktop, XenApp, VDI, HA, XenServer, NetScaler, XenMotion
Компания VMware выпустила интересный документ о продукте для обеспечения катастрофоустойчивости виртуальной инфраструктуры VMware Site Recovery Manager (SRM) 4. В нем описано, каким образом настроить компоненты VMware vSphere 4 и SRM 4 так, чтобы минимизировать время восстановления серверов ESX и виртуальных машин в случае аварии или катастрофы.
Бывает так, что необходимо регламентировать процедуру тестирования отказоустойчивости сетевых интерфейсов VMware ESX (NIC Teaming). В этом случае проверку Network Failover Maish Saidel-Keesing предлагает проводить так:
1. Отключаем один из физических NICs сервера VMware ESX для которого настроен Failover Order, переводя его в режим "10 Half-Duplex ":
[root@esx1 ~]#esxcfg-nics -s 10 -d half vmnic2
2. Видим, что интерфейс отключился:
3. Перед этим запускаем пинги из виртуальной машины, где наблюдаем их потерю из-за "отказа" сетевого адаптера ESX. Потом соединение должно восстановиться по резервному NIC сервера ESX:
4. Включаем интерфейс, переводя его в режим Auto Negotiate:
Компания Starwind, производитель ПО для хранилищ iSCSI для виртуальных инфраструктур, планирует выпуск пятой версии продукта StarWind Enterprise iSCSI SAN. Напомним, что продукт Starwind предназначен для создания iSCSI-хранилища для серверов VMware ESX, Microsoft Hyper-V и Citrix XenServer на базе стандартного Windows-сервера по протоколу iSCSI, к которому, в свою очередь, уже может быть подключена любая система хранения.
Пятая версия позволит получить важнейшую возможность для хранилищ iSCSI - High Availability (HA) или по-русски высокую доступность. Данные в StarWind 5.0 могут синхронно записываться на 2 хранилища iSCSI (Data Mirroring), а в случае отказа основного хранилища, резервное берет на себя нагрузку по поддержанию работы виртуальных машин.
Таги: StarWind, iSCSI, SAN, HA, VMware, Hyper-V, ESX, Veeam
Не так давно вышедшая вместе с Windows Server 2008 R2 бесплатная платформа виртуализации Microsoft Hyper-V 2.0 позволяет строить отказоустойчивые кластеры из хост-серверов. Весь процесс настройки кластера Hyper-V 2.0 можно посмотреть на видео ниже:
Великий Duncanподнял очередную болезненную тему для VMware vSphere. У них (VMware) есть заказчик, у которого 5 хостов VMware ESX в кластере VMware DRS. Вечером, когда нагрузка на хосты ESX спадает, 4 из них переходят в standby режим (делает это механизм Distributed Power Management), остается один хост на котором сервер vCenter, работающий в виртуальной машине.
Если этот единственный хост VMware ESX погибает - вся инфраструктура остается выключенной, поскольку некому вывести остальные хосты из standby и перезапустить vCenter. Все это потому, что Admission Control в настройках кластера VMware HA выключен и отказоустойчивость кластера не гарантирована. То есть это не баг - а фича. Но...
А знаете ли вы, что в VMware vSphere есть не только режим обслуживания (Maintenance Mode) для DRS, но и для High Availability (HA). Режим vSphere HA Maintenance Mode нужен для проведения регламентных работ в сети или устранения неполадок, чтобы механизм VMware HA не срабатывал почем зря и не вызывал действие, указанное в Isolation Responce (например, выключение виртуальных машин).
Для включения режима обслуживания VMware HA нужно просто снять переключатель "Enable Host Monitoring" в настройках кластера VMware HA:
Как многие помнят, в VMware Virtual Infrastructure 3.5 была такая возможность как Virtual Machine Failure Monitoring, о которой мы писали. В VMware vSphere эта возможность доступна из графического интерфейса, называется VM Monitoring и является одной из частей кластера высокой доступности VMware HA. Таги: VMware, vSphere, VMFM, HA, vCenter
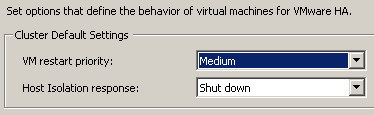
Компания VMware пересмотрела дефолтное поведение кластеров VMware High Availability при отказе хостов VMware ESX. Теперь в случае изоляции хоста ESX от сети, по-умолчанию выполняется действие "Shut down":
Как многим из вас уже известно, новое поколение платформы VMware Virtual Infrastructure, носящее имя VMware vSphere, будет анонсировано 21 апреля. Новые функции VMware Fault Tolerance (FT), расширяющие возможности VMware HA, позволят добиться не просто высокой доступности виртуальных машин, но и их постоянной доступности в случае отказов хостов ESX / ESXi... Таги: VMware, vSphere, VMFT, HA
Сегодня компания VMware объявила о доступности решения vCenter Server Heartbeat 5.5 для обеспечения непрерывной работы серверов VMware vCenter 2.5 (VirtualCenter).
Итак, ключевые особенности продукта Heartbeat... Таги: VMware, vCenter, Heartbeat, VirtualCenter, HA
Не так давно на VM Guru была новость об анонсе продукта VMware vCenter Heartbeat. Сегодня мы расскажем о нем поподробнее, поскольку NDA уже перестало действовать (блоггеры открыли большинство «секретов»).
Итак, основная цель продукта vCenter Heartbeat – постоянная доступность сервера vCenter (VirtualCenter), которой раньше пытались достигнуть сторонними средствами, например, Microsoft Cluster Services. Такая ситуация не устраивала клиентов VMware, которые, во-первых, хотели законченное решение по постоянной доступности от одного вендора, а, во-вторых, защиту на всех уровнях vCenter (WAN failure, компоненты VirtualCenter)... Таги: VMware, vCenter, Heartbeat, VirtualCenter, HA
На блоге для партнеров компании VMware появилось приглашение на вебинар, посвященный продукту VMware vCenter Server Heartbeat... Таги: VMware, vCenter, Heartbeat, VirtualCenter, HA, MSCS

 RSS
RSS




















 ...
...


















